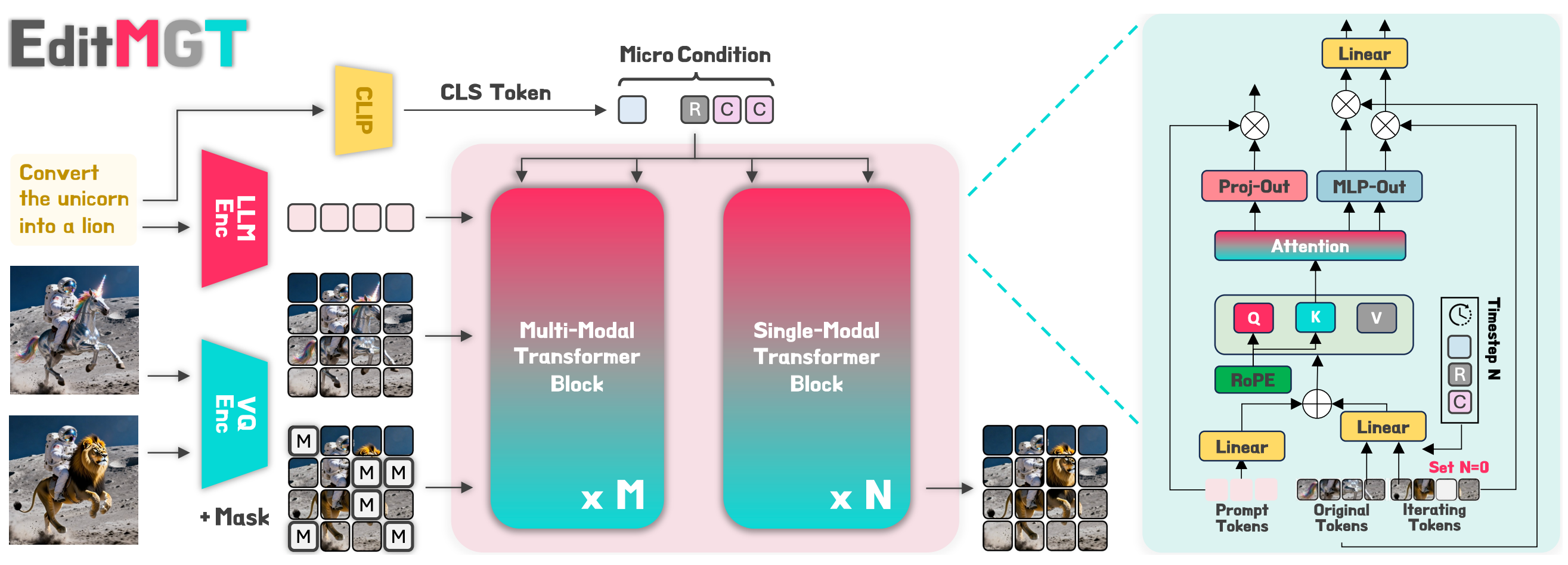
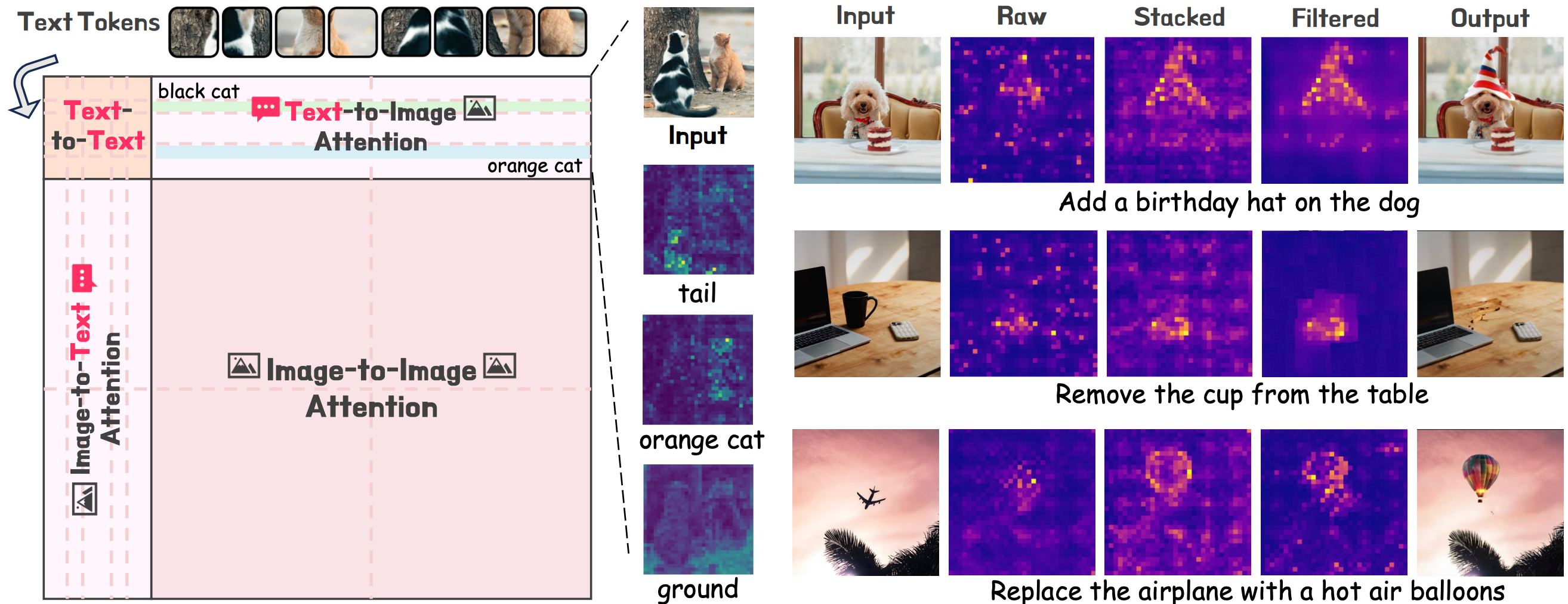
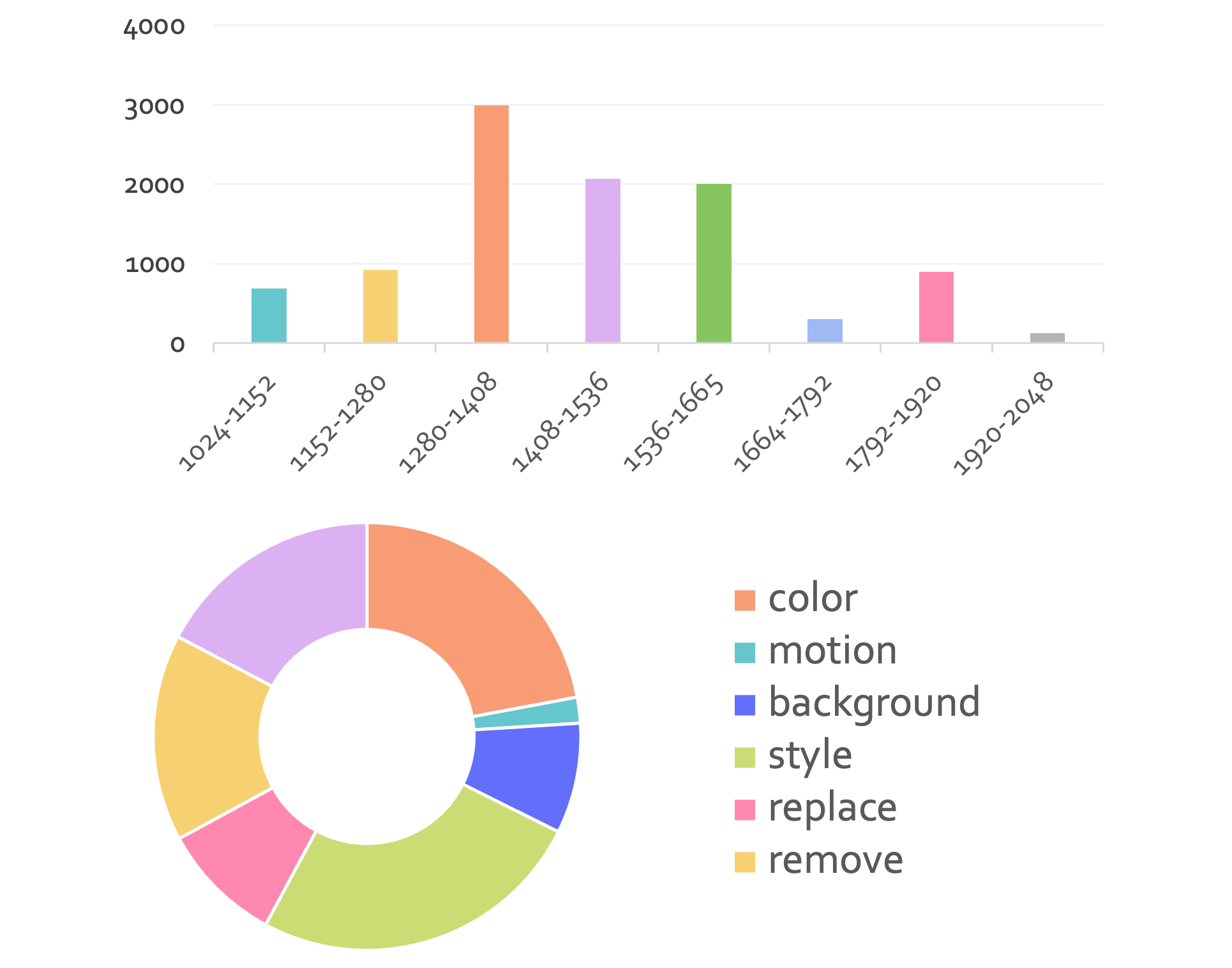
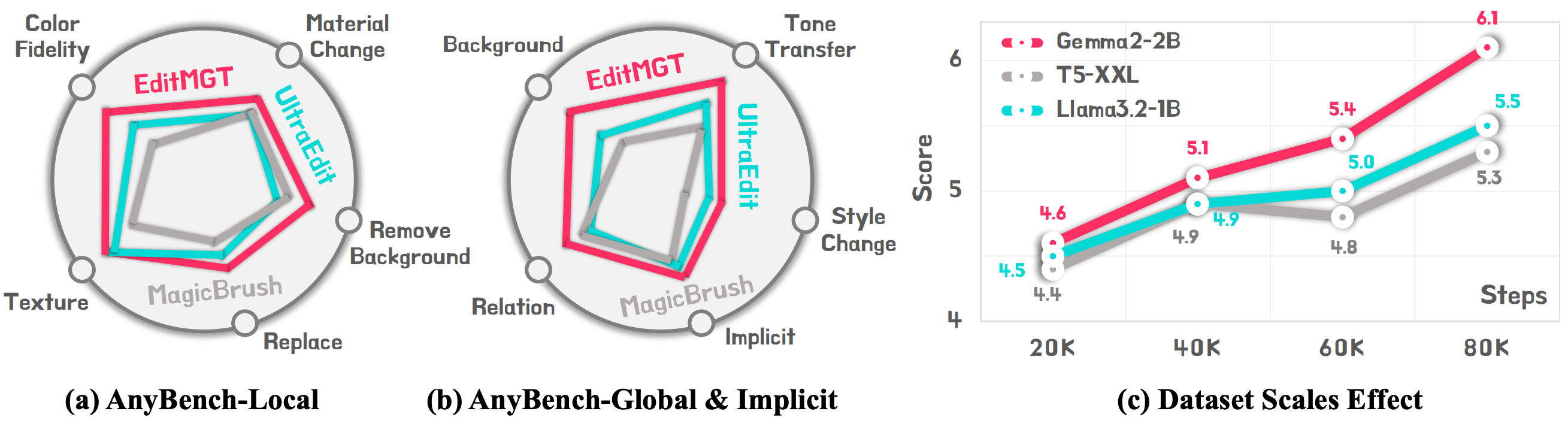
We construct Crisp-2M, a high-resolution image editing dataset spanning 7 distinct categories with 2M samples (short edge ≥ 1024 pixels). Combined with additional high-resolution samples, we utilize 4M total samples for training. This dataset addresses the scarcity of high-quality, high-resolution image editing data, which is crucial for training effective editing models.
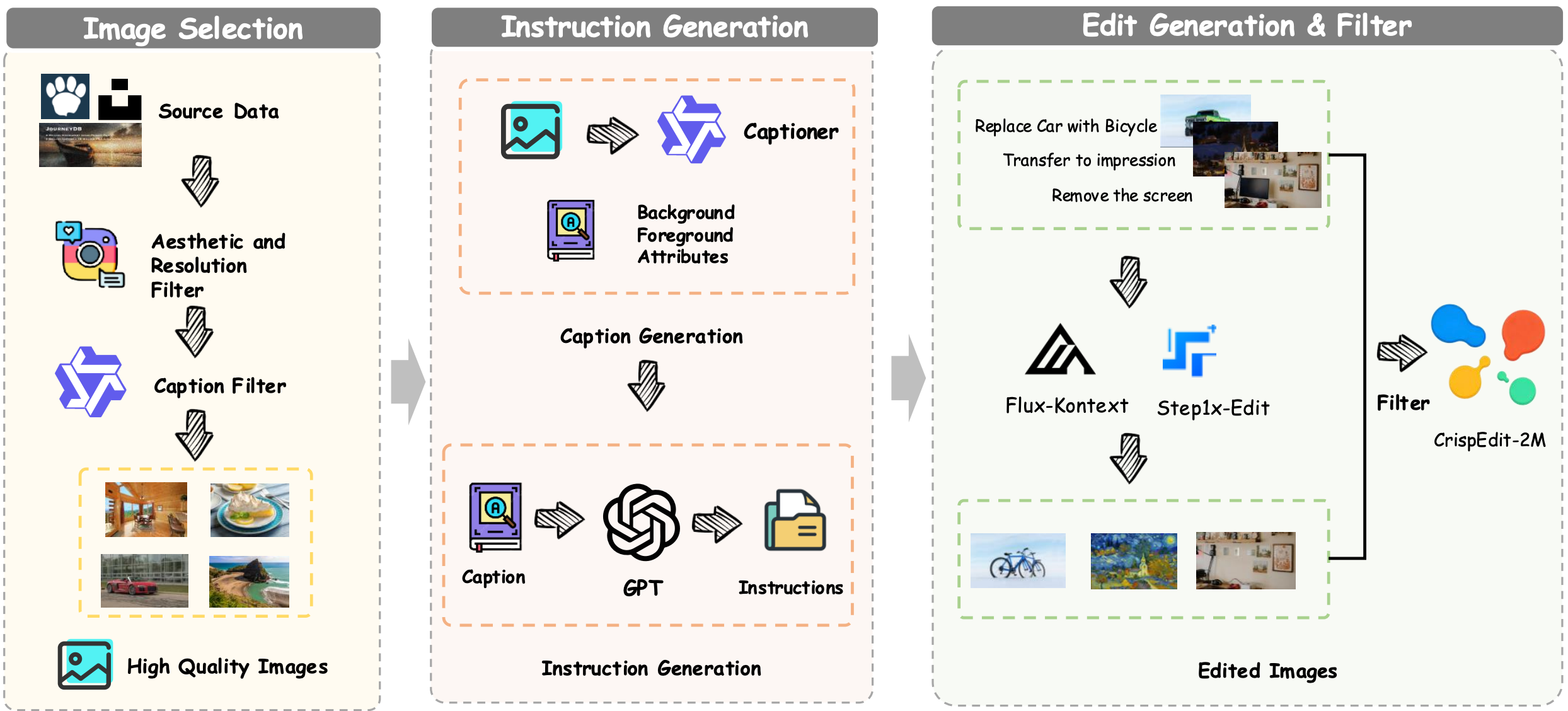
Stage 1: Image Curation. We curate high-quality images from three sources: LAION-Aesthetics, Unsplash Lite datasets, and JourneyDB (FLUX re-generated version). Through systematic filtering based on aesthetic scores above 4.5, resolution requirements (short-side dimensions exceeding 1024 pixels), and content suitability assessment using Qwen3, we obtain approximately 5.5M samples. We employ rigorous filtering to exclude simple patterns, monotonous compositions, and images containing watermarks or text overlays.
Stage 2: Customized Instruction Generation. To enhance data quality and diversity, we propose a systematic two-stage framework. First, we employ Qwen2.5-VL to produce detailed image captions that explicitly delineate background elements, foreground objects, and their semantic attributes. The second stage leverages GPT-4o to systematically transform these descriptive captions into actionable editing instructions across multiple modalities. We implement an iterative self-refinement mechanism that progressively enhances instruction complexity and linguistic diversity.
Stage 3: Specific Edit Pipeline. Our data collection pipeline leverages state-of-the-art models including FLUX.1 Kontext and Step1X-Edit v1.2, subsequently employing VLMs to select superior results. This approach enhances data quality while enriching dataset diversity compared to traditional single-model approaches.
Stage 4: Data Quality Assurance. We establish a comprehensive two-stage filtering framework: (1) Pre-processing instruction validation to identify semantic inconsistencies and logical inconsistencies in LLM-generated instructions; (2) Post-processing quality verification using CLIP-based alignment metrics to ensure semantic correspondence between edited images and target descriptions, and visual similarity metrics to verify preservation of non-target content.